

موتورهای جستجو چگونه صفحات جدید تولید شده وبسایتها را شناسایی می کنند؟
پاسخ این سوال خزنده وب است. نرم افزاری که توانایی پیمایش محیط اینترنت و پیدا کردن و ثبت کردن آدرس URL های جدید را دارد. هسته اصلی تمام موتورهای جستجو خزنده وب آن می باشد. خزنده وب یا کرالر است که اینترنت راکاوش می کند و صفحات جدید را کشف می کند یا صفحات از بین رفته را شناسایی می کند. مکانیزم عمل خزنده های وب جالب است. آنها چگونه صفحات جدید را پیدا می کنند؟
یکی از روشهای پیدا کردن آدرس های جدید وب پیدا کردن آنها در آدرس های قدیمی است. فرض کنید در وبسایت خود مطلبی درج کرده اید که دارای یک URL جدید و منحصر به فرد است. آدرس وب سایت شما قبلا توسط خزنده شناسایی و ثبت شده است و هرچند وقت یک بار به آن سر می زند وآدرس ها و لینکهای داخل صفحه را بررسی می کند. به محض اینکه به لینکی برخورد کرد که آن را در پایگاه داده خود نداشت آن را به بانک اطلاعاتی اضافه می کند. بعد مجدد داخل لینک های صفحه می رود و دنبال لینک های داخل آن می گردد و این فرآیند را تکرار و تکرار می کند. در واقع از لینکی به لینک دیگر و از آدرس به آدرس دیگر می رود و URL های جدید را شناسایی و ثبت می کند. به URL هایی که در حال حاضر در بانک اطلاعاتی خزنده های وب قرار دارد seed یا دانه گفته می شود.
خزنده های وب در حقیقت ربات های نرم افزاری هستند که بی وقفه کار می کنند و در حال رصد کردن وبسایت ها و آدرس های قدیمی و پیدا کردن آدرس ها و وب سایتهای جدید هستند. مشهور ترین آنها google bot و bing bot می باشند. نام دیگر خزنده های وب عنکبوت های وب (webspider), ربات ها (Robots)، فهرست سازان خودکار(Automatic Indexer) می باشد.
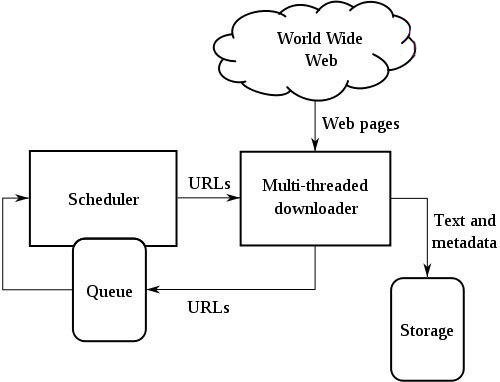
خزنده های وب علاوه بر شناسایی URL های جدید و URL های از بین رفته کار ایندکس گذاری صفحات وب را نیز انجام می دهند. یعنی علاوه بر آدرس، محتوای صفحات را نیز خلاصه و رتبه دهی می کنند. به این ترتیب کیفیت محتوا مشخص می شود و موتور جستجو بنا به کیفیت و ارزش محتوای صفحه وب به آن امتیاز و رتبه می دهد.
همچنین خزنده های وب آدرس را یکدست و نرمال می کنند(URL normalization). یعنی با تبدیل حروف بزرگ به کوچک، حذف قسمت های اضافه آدرس، تبدیل IP به دامنه، حذف پورت، حذف www از آدرس، استاندارد سازی encoding ها و ... آدرس ها را یکنواخت میکنند تا از درج چند آدرس با محتوای شبیه به هم جلوگیری شود. می توان در روت دایرکتوری وبسایت از طریق فایل robots.txt اطلاعاتی از بایدها و نباید های وبسایت را در اختیار خزنده های وب گذاشت.مثلا اینکه کدام directory ها را ایندکس گذاری نکند یامحدودیت های دیگری از این قبیل




